
データベースのI/Oにまつわる誤解
今回は、非正規形が実際は遅いことを説明するために、I/Oにまつわる誤解について解説していきたいと思います。
ここから先の説明はPostgreSQLおよびOracleをベースとしています。
MySQLやSQLServerなど別のDBMSでも大筋は同じはずですが、詳しくは個別にご確認ください。
前回の記事で、次の理解は間違いであると述べましたが、今回は赤字の部分について説明していきます。
非正規化すると、必要な情報が1レコードの中に揃っている
↓
1レコードに情報が揃っているので、1回のI/Oで必要な情報が全部取れる(JOINがない)
↓
1テーブルだけが対象なのでSQLの記述が少なく済む(シンプル)
ここで言うI/Oとは、データベースとストレージ(HDDやSSDなど)間の読み書きを指します。
ここで間違っている点は、1回のI/Oの単位を「レコード」としていることです。イメージとして次の図のようになりますが、これは誤りです。
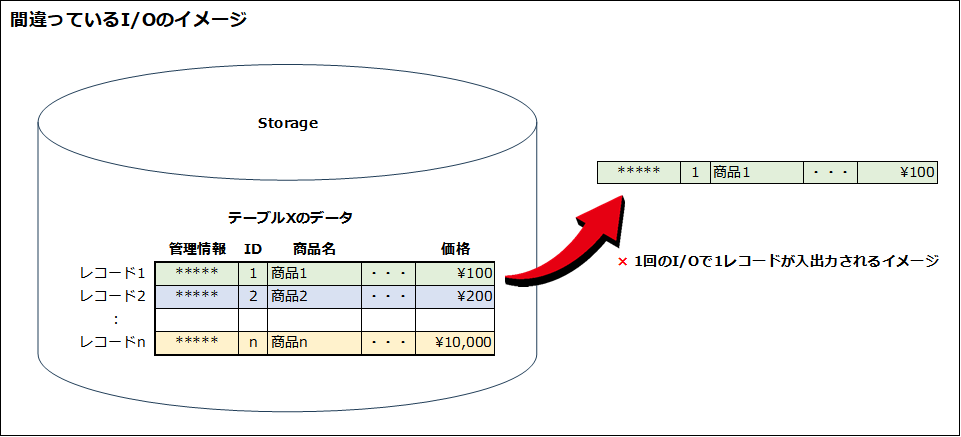
実際には、1回のI/Oの最小単位は「ページ」ないし「ブロック」です。
ページ: PostgreSQLにおけるI/Oの最小単位(8KB固定)
ブロック: OracleにおけるI/Oの最小単位(2~32KB。デフォルト8KB)
各レコードは、ページ/ブロックを境界とする領域に連続的に詰めて格納されます。
1レコードのサイズが1ページ/ブロックに収まる場合、1回のI/Oではその中の複数のレコードが一括で取得されます。
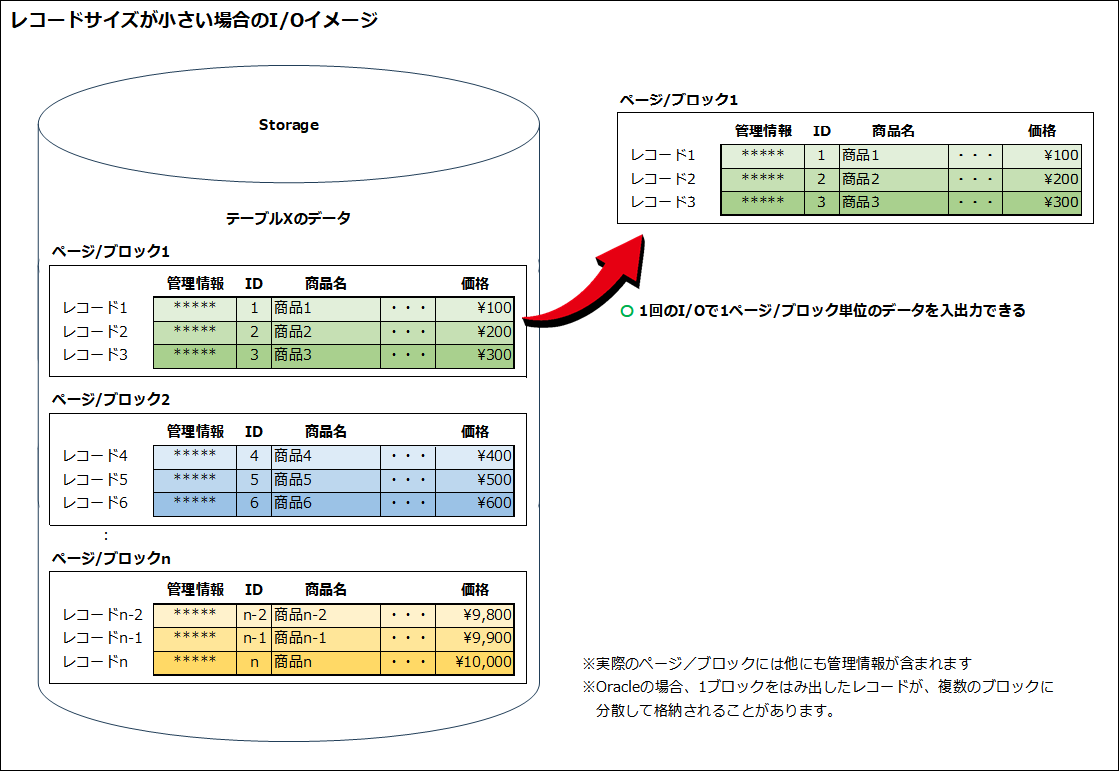
1レコードのサイズが1ページ/ブロックに収まらない場合、1レコードのデータを分割して別の領域に格納した状態となるため、複数回のI/Oが必要になります。
この動作は、PostgreSQLとOracleで少し異なります。
- PostgreSQLでは、1ページに収まらないレコードや2KBを超えるカラムをTOASTという別の領域に、
2KBごとのチャンクに分割して格納します。 - OracleにはTOASTの仕組みはなく、1ブロックに収まらないデータを複数のブロックに分けて格納します。レコードを分割して格納するという点は同じです。
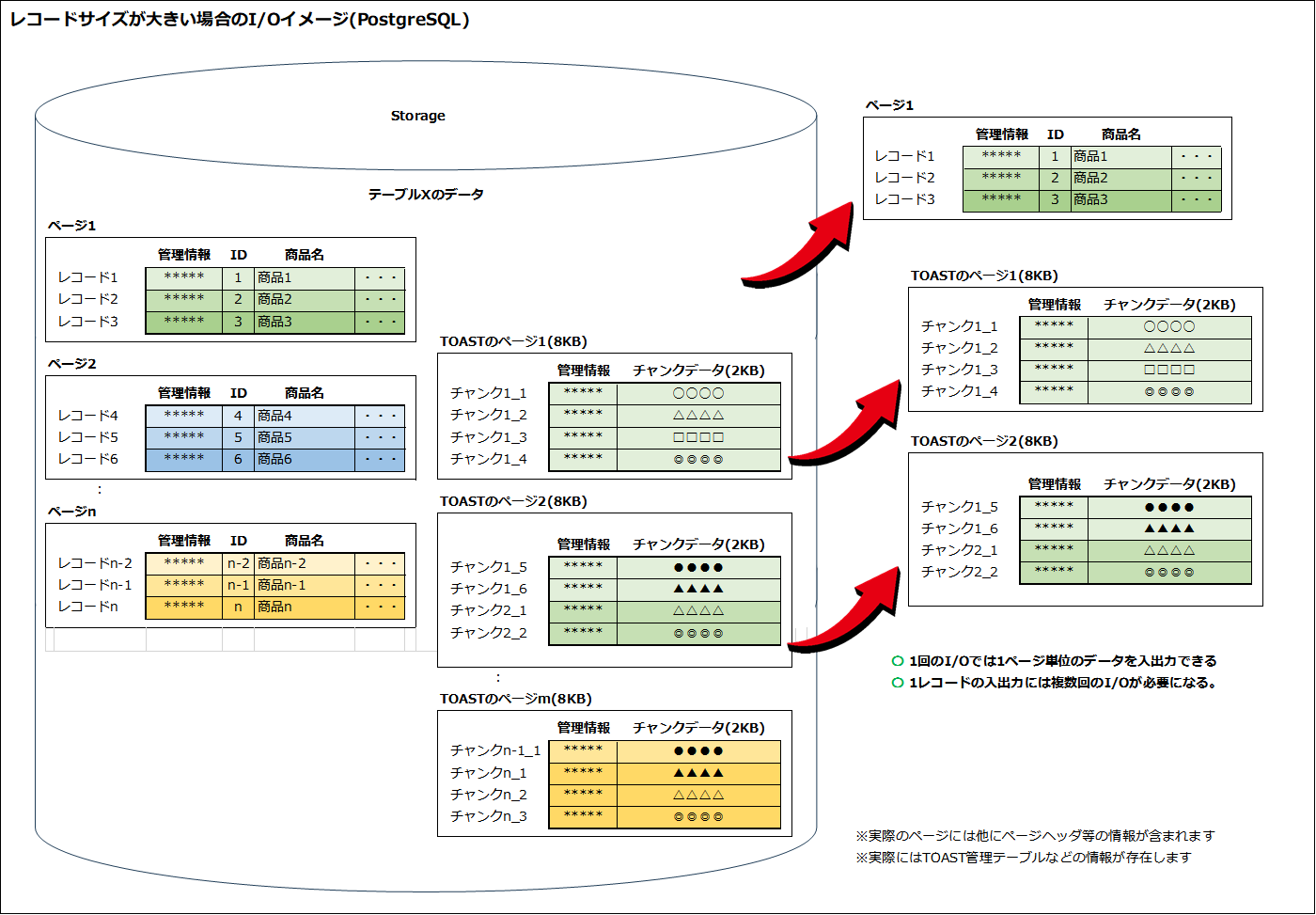
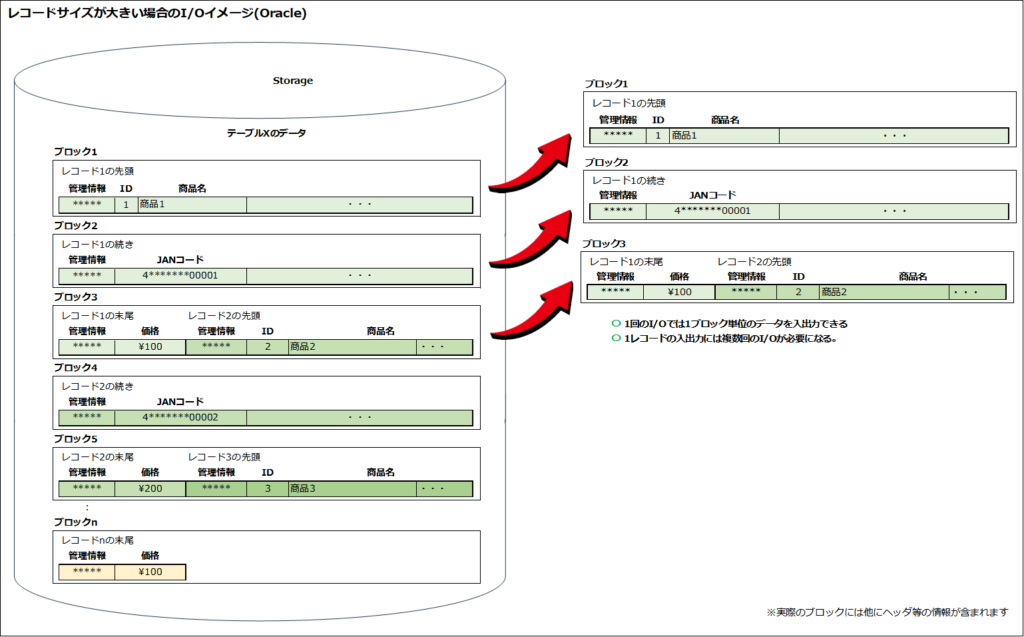
実際にはキャッシュ・インデックス・WALの動作なども加味する必要がありますが、この動作が基本です。
以上の仕組みは、レコードのサイズがI/Oの発生回数に大きな影響を与えることを意味しています。
- 1レコードのサイズがページ/ブロックのサイズより小さければ、1ページ/ブロックに複数のレコードを格納できるため、1回のI/Oでより多くの情報を取得できることになります。
これは特に、シーケンシャルなアクセスをする場合に効率的です。 - 逆に1レコードのサイズがページ/ブロックのサイズを超えると、TOASTや複数のブロックを読み込む必要があり、I/Oの回数が増えます。
たとえ1レコードの中で取得したい情報が1カラムだけだったとしても、常に1レコード全体を読み込むため、複数のI/Oが発生します。
これは効率的とは言えない状態です。
正規形でJOINによるI/Oが発生することばかり強調されますが、レコードサイズが大きくなることでもI/Oは増えるのです。
I/Oの重要性
なぜデータベースのI/Oがこんな面倒な仕組みなのか、疑問に思われると思いますので、その理由を解説します。
これは、ファイルシステムとストレージの特性に合わせて最適化した結果です。
HDDやSSDの特性として、メモリのように任意の1byteを読み書きできるわけではなく、以下を物理的な最小単位として読み書きを行います。
- HDDの場合はセクタ(512byteや4KB)
- SSDの場合はページ(4KBや16KB)
これに合わせてファイルシステムは、ブロックを最小単位(主に4KB)として読み書きを行います。
ストレージ-ファイルシステム-データベースの間でこの単位がうまい具合に揃っている状態では、パフォーマンスは良好です。これが崩れると、無駄なヘッダの移動や読み書きなどでオーバーヘッドが発生します。
SSDの場合では比較的ランダムアクセスに強いものの、このオーバーヘッドを無視できるほどではありません。一般的にHDDやSSDのI/Oにかかる時間は、CPU処理やメモリアクセスと比べて1,000倍から10,000,000倍といった差になりますので、この点は性能に大きく影響します。
非正規化を行うと、カラム数が増えることでレコードサイズが増大します。大きなシステムでは、1レコードに数百から数千のカラムを持つテーブルになる状況も珍しくありません。
そのようなテーブルでは、1レコードあたり数百回といったI/Oが発生することになります。この負荷はJOINの負荷を上回るだけでなく、すべてのSQLでの性能低下につながります。
ここまで理解すれば、レコードサイズの増大に伴うI/Oの増加が、いかに性能上不利となるかが分かると思います。
非正規化の例え
この問題をより具体的にイメージするために、データベースを倉庫に例えてみます。
- 1つのカラムは、商品を構成する1個のパーツを表す。
- 1つのレコードは、複数のパーツが集まってできた1つの商品を表す。
商品を構成するパーツはまとめられ、パッケージングされる。
ただし一定(8KB)以上大きい場合は取り回ししづらいので、n個組のように複数のパッケージに分けられる。 - 1ページ/ブロックは、商品を集めて格納する段ボール箱を表す。
ただし段ボール箱は追加したり空きを再利用するので、n個組となった商品のパッケージが、同じ段ボール箱に格納されるとは限らない。 - 1つのテーブルは、商品を入れた段ボール箱を置くための棚を表す。
商品が倉庫のどこにあるかは、検索可能なようにインデックス化される。
倉庫から商品を出し入れするときは段ボール箱の単位で運び、所定の作業場所で開封しなければならない。 - あなたはデータベースであり、倉庫番である。
指示を受けて上記のルールに則り商品を出し入れする役目である。
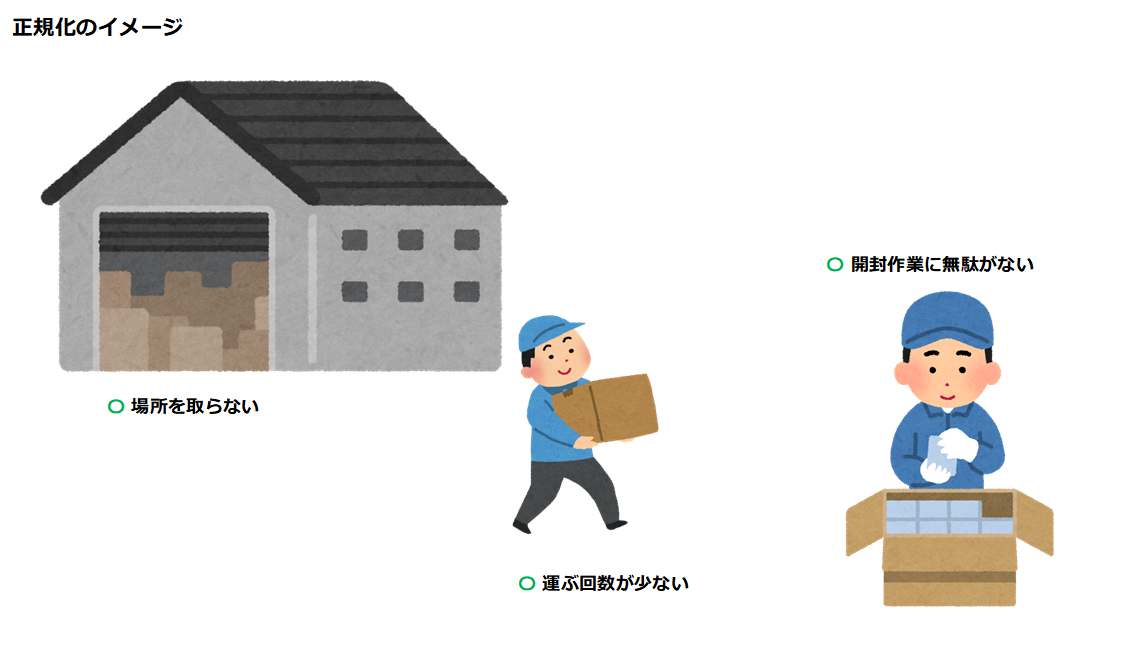
正規化した場合では、商品を構成するパーツが最小限となり、パッケージが小さく済みます。
1つの段ボール箱に複数の商品を収められる状態であれば、1回の運搬でより多くの商品を運ぶことができます。また、段ボール箱を1つ開けるだけで目的の商品やパーツを出し入れできます。
この状態での作業は、たとえ多種類の商品を取り扱う(=JOINが発生する)場合においても最小限の労力で済むため、効率的です。
一方で非正規化した場合は、商品を構成するパーツが多くなり、1つの商品がn個組に分割された状態が発生しやすくなります。
仮に1つの商品が10個の段ボール箱に分割されたとすると、あなたは1つの商品を運び出すために倉庫全体を回って目的の段ボール箱を探し出し、10回に分けて運搬・開封する必要があります。さらに目的が1つのパーツだけだったならば、9回の運搬と開封の作業は無駄でしかありません。
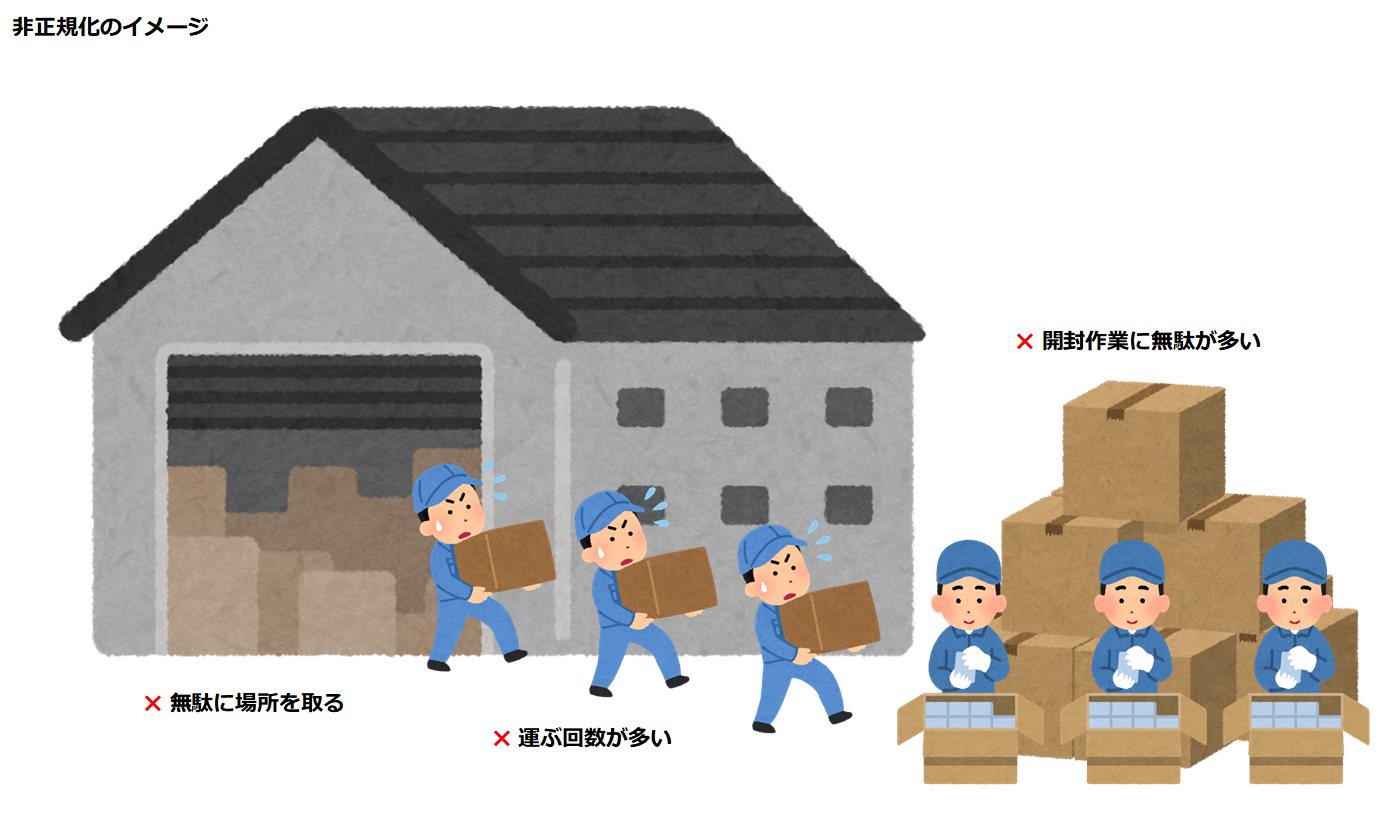
こうして人の動きに置き換えてみると、非正規化が大きな無駄と重労働を生み出すことがイメージできるのではないでしょうか?
非正規形が性能的に有利に働くのは、1レコード全体を読み込んでも無駄がない場合に限られます。この条件では、複数のテーブルをJOINするよりいくらか速い可能性もあります。
しかしそのような限定的な条件のために、他のすべての性能を犠牲にする必要があるでしょうか?
レコードサイズは最小限に保つべきです。そのための最適な形が、正規形です。
次回は、非正規化により実際にどれくらい性能が低下するのか、測定と検証を行いたいと思います。
 (まだ評価がありません)
(まだ評価がありません)
