
正規化だけではうまくいかない
前回の記事の最後で、正規化に関して様々な議論があることに言及しました。
今回から数回に分け、「正規化してみたが、どうもうまくいかない」という問題について、解説したいと思います。
大前提としてデータベースの正規化は重要ですが、それさえ行っていれば万事解決という訳ではありません。
教科書通りの正規化を行うことは難しくありませんが、「適切な正規化」を行うにはいくつかのコツがあります。そこでは、正規化では定義されていない設計についての考慮が必要です。
考慮すべきポイントはいくつかありますが、今回は「テーブル分割の設計」について解説します。
テーブルをどう分割するか
正規化の定義は、冗長性と論理矛盾の排除を目的としたものです。正規形の定義について確認してみます。
第一正規形: 繰り返し項目の排除
第二正規形: 部分関数従属の排除
第三正規形: 推移的関数従属の排除
ボイス・コッド正規形: 非キーから主キーへの関数従属性の排除
第四正規形: 多値従属の排除
第五正規形: 結合従属の展開
これらは「項目間の従属性」という観点に基づき、テーブルを分割することを定義しています。逆に言えば、以下の観点でのテーブル分割については定義がありません。
- データの性質(マスタ・トランザクション・サマリ)
- データの意味的なまとまり
- データが発生・消滅するタイミング(ライフサイクル)
したがってこれらの観点は、正規化とは別に設計する必要があるということです。
各観点について、ひとつずつ解説します。
観点1: データの性質に基づくテーブル分割
データベースに格納するデータを性質で分類すると、以下の3つに分かれます。
マスタ: システムを構成する基礎データ
トランザクション: システムの運用に伴い日々発生・消滅するデータ
サマリ: マスタ・トランザクションを集計・集約したデータ
ここで重要なことは、異なる性質のデータが同じテーブルに混在してはならないということです。
異なる性質のデータが混在する状況は、例えば以下のようなケースで発生します。
- 本来マスタとして切り出すべきデータを、面倒なのでトランザクションテーブルに含めてしまう
- 非正規化を行った結果として、マスタやトランザクションのテーブルにサマリデータを入れてしまう
a.のケースでは、最初は正規形を保てるのかもしれません。
しかし後の設計変更でテーブルやカラムが増え、マスタであるべき情報を複数個所で持つことになると、推移的関数従属やデータの冗長性が発生し、結果として正規形が壊れることになります。
b.のケースはサマリなのでそもそも正規化に反しますが、サマリデータをマスタやトランザクションのテーブルに含めることで、より状況が悪化します。
- サマリの集計処理により、マスタ・トランザクションに対して本来必要ない更新とロックが発生する
- サマリ項目の分レコードサイズが増大し、I/O性能が低下する
- 集計のタイムラグやデータの更新漏れにより、データの一貫性が損なわれた状態が発生する
- これらの状況に対応するため、プログラムや運用保守が複雑化する
本来は非正規化をするべきではありませんが、私は以下の条件で設計したサマリに限り、許容しています。
- サマリデータだけ切り出したテーブルとし、マスタ・トランザクションの正規形を崩さない
- サマリデータは、高負荷な集計処理の実行頻度を減らす目的で作成する
- サマリデータには原子性・一貫性がないため、判定などには使用しない(主に表示目的)
この条件下であれば、非正規化しても集計負荷以外の副作用を抑えることができます。
次のER図は、性能編で定義した正規形2の例です。
この例ではテーブル名に必ずマスタ・トランザクション・サマリとつけることで、データの性質に基づいてテーブル分割していることを明示しています。
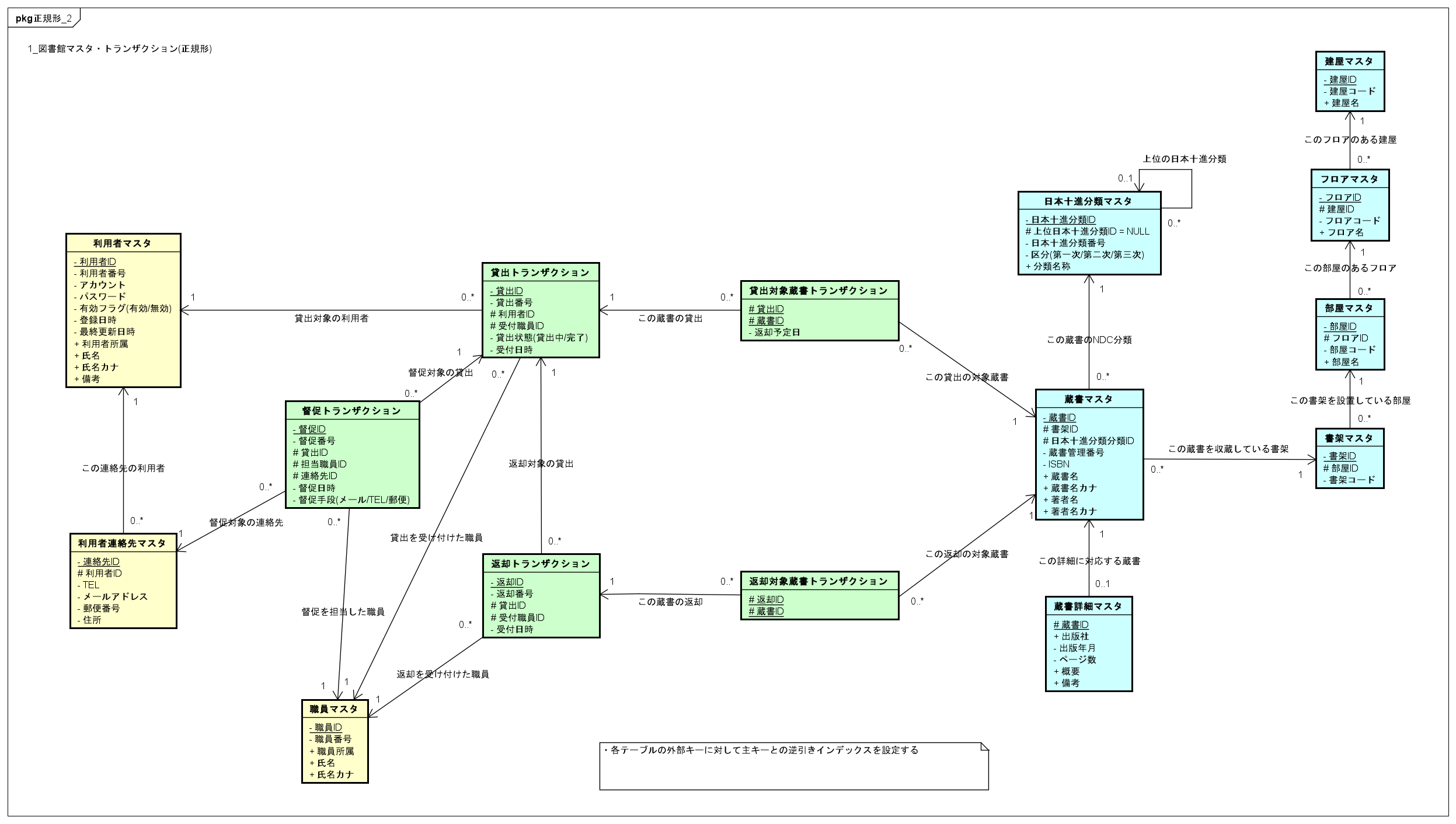
観点1のまとめとして、各データがマスタ・トランザクション・サマリのどれに該当するかを明確にし、テーブルを分割する必要があります。
観点2: 意味的なまとまりに基づくテーブル分割
テーブル分割の設計として、次に「データの意味的なまとまり」を考慮する必要があります。
例えば一個人を表すデータを考えたとき、以下のように様々な属性が考えられます。
基本的な属性:
- 氏名(日本語表記・カナ表記・英語表記)
- システム内で個人を特定する番号(従業員番号など)
組織に関する属性:
- 所属する組織(組織マスタへの外部キー)
- その組織における身分(身分マスタへの外部キー)
戸籍に関する属性:
- 生年月日
- 性別
- 旧姓・通称
- マイナンバー
- 本籍地の住所
- 居住地の住所
個人認証に関する属性:
- ユーザIDとパスワード
- 多要素認証データ(指紋・顔写真・登録スマホなど)
これらの情報の性質はマスタになりますので、観点1に基づきひとつのマスタに収めても正規化には矛盾しません。
しかし、次のような問題が発生するでしょう。
- レコードサイズが増大してI/O性能が低下する
- 常に不要なデータを含むレコードとして処理される分、I/Oに無駄がある
- 運用上設定されないデータが発生する(NULL項目)
aとbについては、性能編で詳しく解説した通りです。
cについては軽視されがちですが、実は極めて大きな問題なので詳しく解説します。
NULL項目が引き起こす問題
通常、システムが何かの判定や処理に使うカラムには、NOT NULL制約をつけてデータが存在することを保証します。
もしNOT NULL制約がない場合、そのカラムを使用するすべてのプログラムは、NULLの場合の対応を個別に実装する必要が発生します。
SQLの場合: IS NULLによる条件判定・coalesceによる変換・count等の集計時の考慮など
外部プログラムの場合: Null Pointer Exceptionに対する考慮など
該当するカラムやプログラムが少ないうちはあまり問題に感じないかもしれませんが、これが数十・数百となってくると深刻な問題となります。
- NULLの影響を受けるすべての個所で、NULLへの対応を実装する必要がある
- NULL対応の処理が正しく働くか・漏れがないかテストする必要がある
言うは易しですが、このような対応はすぐに数千・数万stepの実装と、同数のテスト項目となって跳ね返ってきます。実際にこの対応が完璧にできているシステムは少なく、部分的な対応に留めるか、「NULLのデータは発生しないはず」という危うい前提で動いているケースが多いでしょう。
これが原因で、考慮漏れや想定外のシステム障害を引き起こす事例をよく見かけます。
ただひとつNOT NULL制約があれば、これらの対応はすべて必要なくなります。NULL対応の実装とテストは、本来はデータ入力処理の1箇所だけで良いのです。
したがってNOT NULLを設定できない状態は、大きな無駄と品質の低下を生み出すということです。
少し余談となりますが、NOT NULL制約が重要である点について補足します。
リレーショナルデータベースが登場する以前の「カード型データベース」では、リレーションの概念がなく、一連の情報をひとつのテーブル(カード)に収める必要がありました。
カード型データベースにもNOT NULL制約はありましたが、テーブルを分割できない制限の下では存在しないデータも含めてレコードを登録する必要があるため、どうしてもNULL値を許容せざるを得ないケースが多発しました。
その結果、カード型データベースでは巨大なテーブルと大量のNULL項目が発生し、システムが複雑化してしまうことが大きな課題でした。
これを解決するために、リレーショナルデータベースが誕生しました。
リレーションの概念によりテーブル分割が可能となり、NOT NULL制約を活用できるようになりました。
こうした歴史から分かるように、NOT NULL制約を可能とすることは、データベース技術の一大目標だったのです。
a~cで挙げた問題を引き起こさないためにはいくつかの考慮が必要ですが、そのひとつが「データの意味的なまとまり」に基づくテーブルの分割です。
極端なことを言うと第5正規形ですべてのカラムをテーブルに分割してしまう方法もありますが、それではさすがに実装が煩雑で、性能も出なくなります。
そこで適度な分割方針として、以下の観点の分類に基づきテーブルを分割します。
- 意味的に関連性がある
- セットで必要となることが多い(アクセス頻度が高い)
- 分類したデータ間に親子関係を持たせる
個人データの例をER図にすると、以下のようになります。
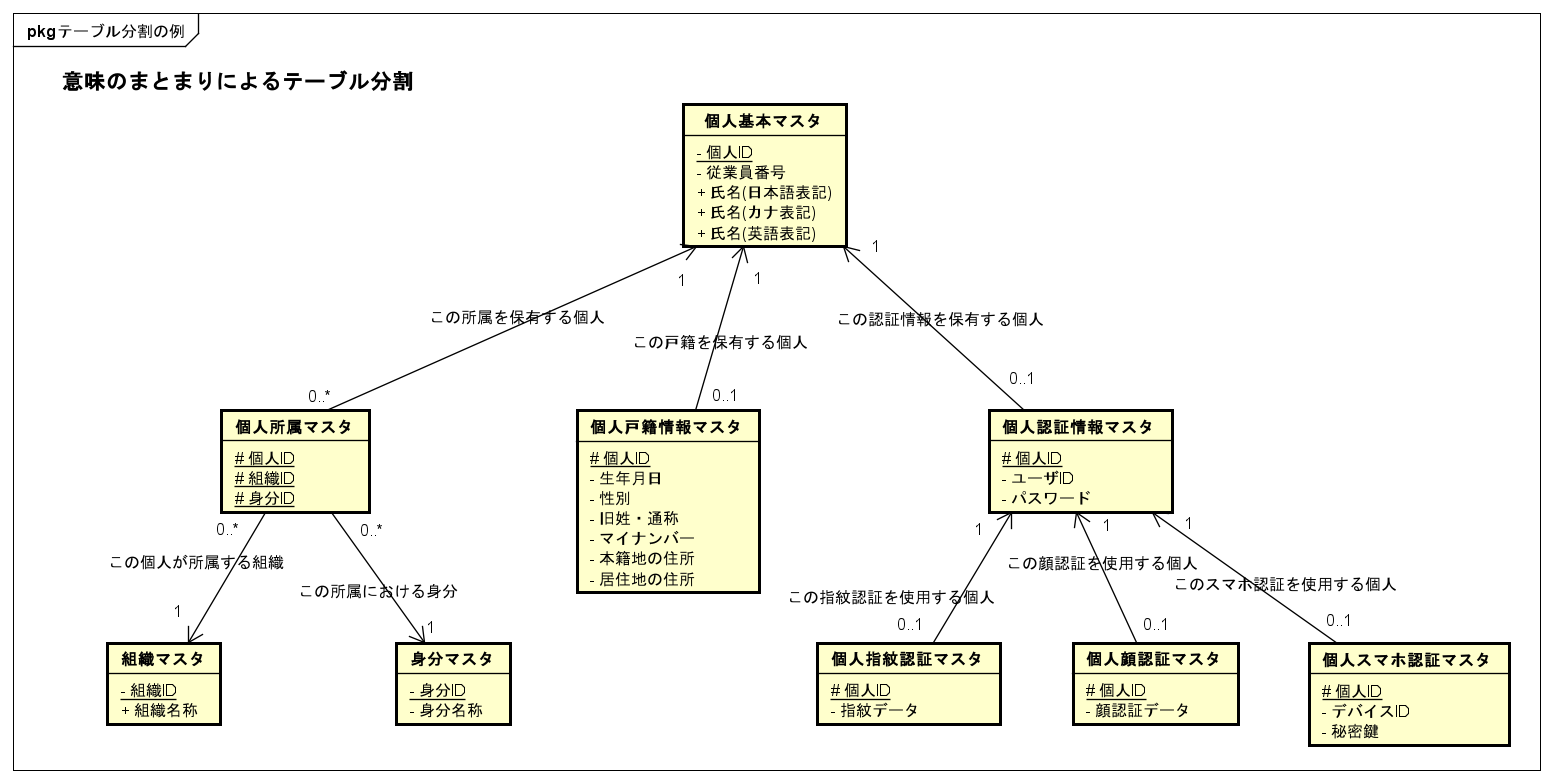
どこまで細かく分割するかは要件次第ですが、ある程度細かい方がレコードサイズが小さくなり、性能面で有利に働くことは性能編で解説した通りです。特に蔵書マスタの例では、アクセス頻度の低いカラムを別テーブルに分離したことで、大きく性能が向上しました。
また第5正規形で定義されているように、適度にテーブルを分割しておくことは、仕様上の柔軟性を持たせる効果もあります。
以上が「意味のまとまりによるテーブル分割」の解説となりますが、この中でひとつ説明していない観点があります。
それについては、引き続き観点3として解説します。
観点3: ライフサイクルに基づくテーブル分割
最後の観点として、「ライフサイクルに基づくテーブル分割」を説明します。
データのライフサイクルとは、どのタイミングでデータが発生・消滅するかということです。
すべてのデータが常に同時に発生するとは限りません。観点2で挙げた例では、ライフサイクルに次の違いがあります。
| 対象データ | 登録のタイミング | 更新のタイミング | 削除のタイミング |
|---|---|---|---|
| 個人基本マスタ | 会社に採用された | 結婚等で氏名に変更があった | 退職した |
| 個人所属マスタ | 配属が決定した (採用直後は未配属の状態) | 異動が発生した | 異動が発生した 退職した |
| 個人戸籍情報マスタ | 会社に戸籍情報を提出した | 住所変更があった 結婚等で旧姓が発生した | 退職した |
| 個人認証情報マスタ | アカウントが発行された | ユーザIDを変更した パスワードを変更した | 退職した |
| 個人指紋認証マスタ | 指紋登録を行った | 指紋を再登録した | 指紋認証を解除した 退職した |
| 個人顔認証マスタ | 顔写真登録を行った | 顔写真を再登録した | 顔認証を解除した 退職した |
| 個人スマホ認証マスタ | スマホ登録を行った | 機種変更を行った | スマホ認証を解除した 退職した |
ここで重要なことは、ライフサイクルの異なるデータが同じテーブルに混在してはならないということです。
もしライフサイクルが異なるデータが混在すると、そのテーブルにはNULL項目が発生します。
観点2で説明した通り、NOT NULLを設定できない項目には煩雑なNULLチェックが必要となり、その実装とテストには多大な労力がかかります。可能な限りNOT NULL制約を設定できるように設計すべきです。
観点2で挙げたER図では、すでにライフサイクルを考慮してテーブルが分割された状態になっています。
ライフサイクルが同じデータ同士をテーブルにまとめることで、以下の効果が生まれます。
- NOT NULL制約を適切に設定できる
- JOINを使ってSQLをシンプルに記述できる
- 処理上で必須とするデータは、INNER JOINで処理できる
- INNER JOINできないデータは、無効データとして処理対象から除外する
- 処理上で必須でないデータは、LEFT OUTER JOINで処理できる
- 処理上で必須とするデータは、INNER JOINで処理できる
JOINの効果は副次的なものですが、NULL項目を回避するという点において、ライフサイクルの考慮は必要不可欠です。
以上が、「ライフサイクルに基づくテーブル分割」の解説となります。
まとめ
観点1と観点2は、比較的できているシステムが多いと思います。
しかし観点3について考慮できていないことで、NULL項目の発生が抑えられず、設計が泥沼化しているケースをよく見かけます。
整理すると、テーブル分割の設計では、正規化に加えて以下の観点が必要です。
- 性質(マスタ・トランザクション・サマリ)が異なるデータを同じテーブルに混在させない
- NULL項目を回避するために、以下の観点でのテーブル分割も必要
- 意味的なまとまりでテーブルを分割する
- ライフサイクルの異なるデータを同じテーブルに混在させない
この観点以外にも、セキュリティや仕様変更を考慮してさらにテーブルを分割する設計もあると思います。そのあたりは設計の自由度の範囲ですので、要件に基づき個別にご判断下さい。
今回は「正規化がうまくいかない」原因のひとつとして、テーブル分割の設計を解説しました。
次回は別の原因として、主キー設計について解説したいと思います。

 (1 投票, 平均: 3.00 / 5)
(1 投票, 平均: 3.00 / 5)
